【转】浅谈服务发现
本文转自:https://blog.csdn.net/Mr_SeaTurtle_/article/details/77618403
2017年08月27日 09:19:13
引言
随着微服务的大范围应用,服务发现这个词也变的越来越火热。下面这篇文章,就会对服务发现这个概念进行介绍,介绍主要包含三部分,服务发现的定义,服务发现的模式以及目前比较成熟的服务发现应用。
服务发现是什么?
其实,我们日常的很多普通操作,都是在做服务发现。
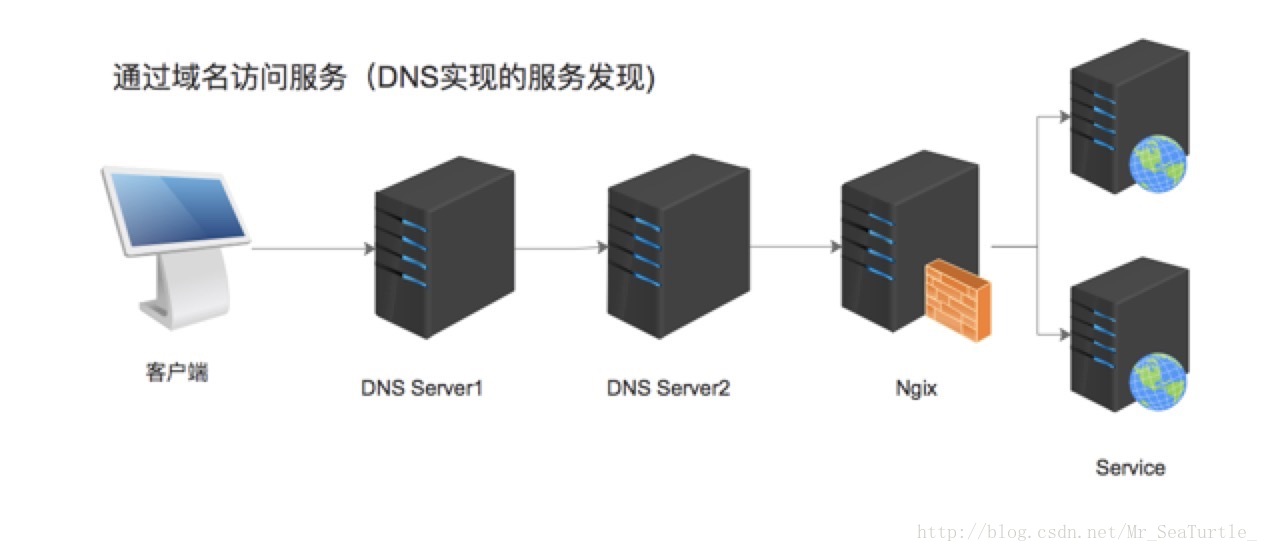
如上图所示,这是一个在浏览器输入域名,然后获取网站服务的流程。这个流程中,DNS服务器会根据我们的域名解析出一个ip地址,返回ip地址中对应链接包含的内容。我们根据特定的标志(域名)来获取我们所需要的服务,这就是服务发现。而在微服务的领域,我们将应用拆分成一个个的微服务之后,服务发现,则变成了微服务之间相互获取彼此的信息。
然而,在微服务的场景下,使用DNS服务器作为服务发现的实现者会存在以下几个问题。
DNS服务器不支持动态变更,不能够随着服务的状态变更(上线、下线、故障)而对域名映射变更。
DNS只能支持域名和ip地址的一一映射,但在微服务的场景中,很多微服务都会部署多个实例,这也就要求标志与服务要有一对多的映射。
DNS服务无法解决多数据中心的问题。
总的来说,服务发现就是程序如何通过一个标志来获取服务列表,并且这个服务列表是能够随着服务的状态而动态变更的。
服务发现的模式
目前,服务发现主要存在有两种模式,客户端模式与服务端模式,两者的本质区别在于,客户端是否保存服务列表信息。下面用两个图来表示客户端模式与服务端模式。
客户端模式
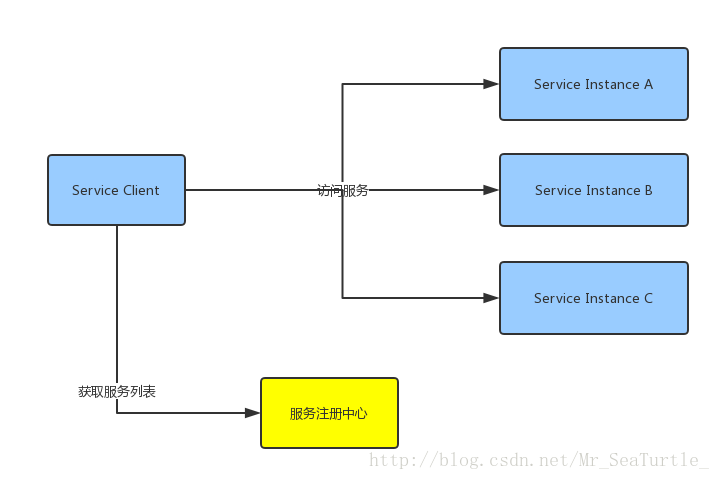
在客户端模式下,如果要进行微服务调用,首先要进行的是到服务注册中心获取服务列表,然后再根据调用端本地的负载均衡策略,进行服务调用。
服务端模式
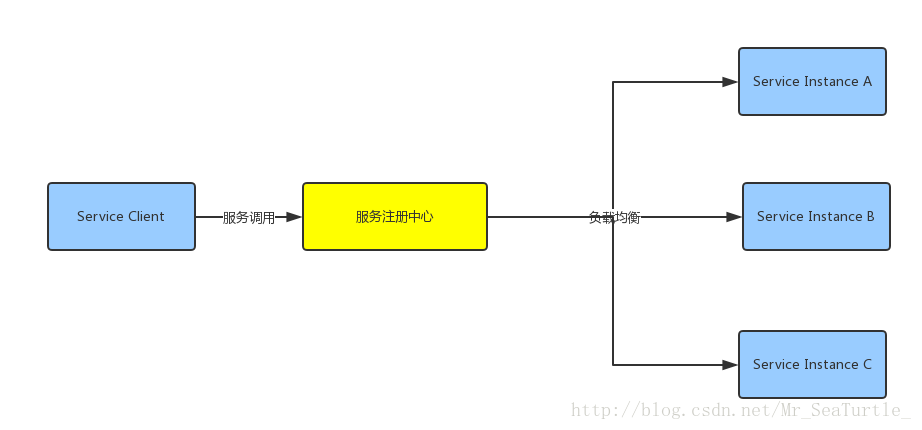
在服务端模式下,调用方直接向服务注册中心进行请求,服务注册中心再通过自身负载均衡策略,对微服务进行调用。这个模式下,调用方不需要在自身节点维护服务发现逻辑以及服务注册信息,这个模式相对来说比较类似DNS模式。
对两者进行对比的话,他们的优劣也十分的明显
| 客户端模式 | 服务端模式 |
|---|---|
| 只需要周期性获取列表,在调用服务时可以直接调用少了一个RT。但需要在每个客户端维护获取列表的逻辑 | 简单,不需要在客户端维护获取服务列表的逻辑 |
| 可用性高,即使注册中心出现故障也能正常工作 | 可用性由路由器中间件决定,路由中间件故障则所有服务不可用,同时,由于所有调度以及存储都由中间件服务器完成,中间件服务器可能会面临过高的负载 |
| 服务上下线对调用方有影响(会出现短暂调用失败) | 服务上下线调用方无感知 |
目前来说,大部分服务发现的实现都采取了客户端模式。下面就会对两种比较经典的服务发现框架进行介绍
几种服务发现框架的简介
在这一小节中,我们将会通过三个方面以及一些具体的例子来介绍服务发现框架是如何工作的,它们各自的特点又是些什么。包括如何对服务进行注册/反注册,在CAP(一致性,可用性,分布式)之间的选择。
Eureka
eureka是netflix用于服务注册和发现的框架。在这个框架中,分为server和client两种角色。server负责保存服务的注册信息,同时server之间也可以彼此相互注册,client则需要向特定的server进行注册。
服务注册/反注册机制
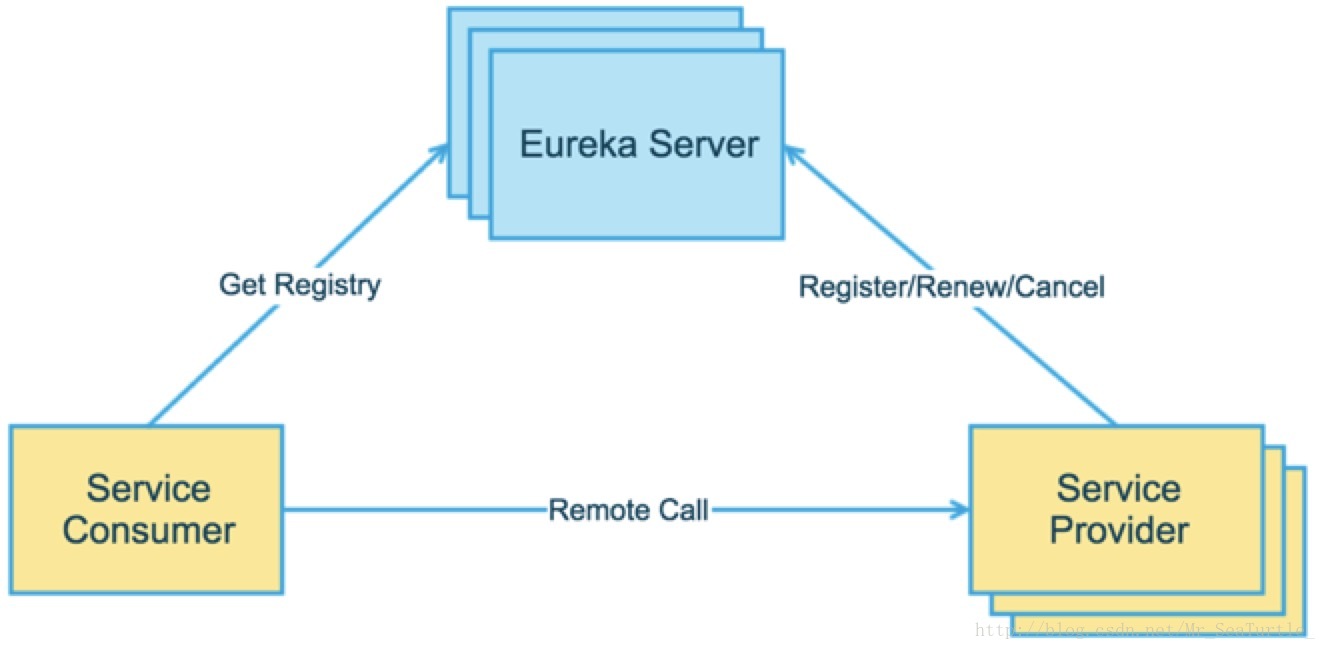
图片来源:携程技术中心
如上图所示,Eureka采用了客户端的模式,服务首先需要向注册中心注册,调用方则需要在本地维护一个服务注册列表。
具体的操作为:client/server通过RESTful Api向server进行服务注册,并且定期调用renew接口来更新服务的注册状态,若server在60s内没有收到服务的renew信息,则该服务就会被标志为下线。而如果服务需要主动下线的话,向server调用cancel就可以了。
Eureka同时支持多个注册中心,以保证注册中心的高可用性。
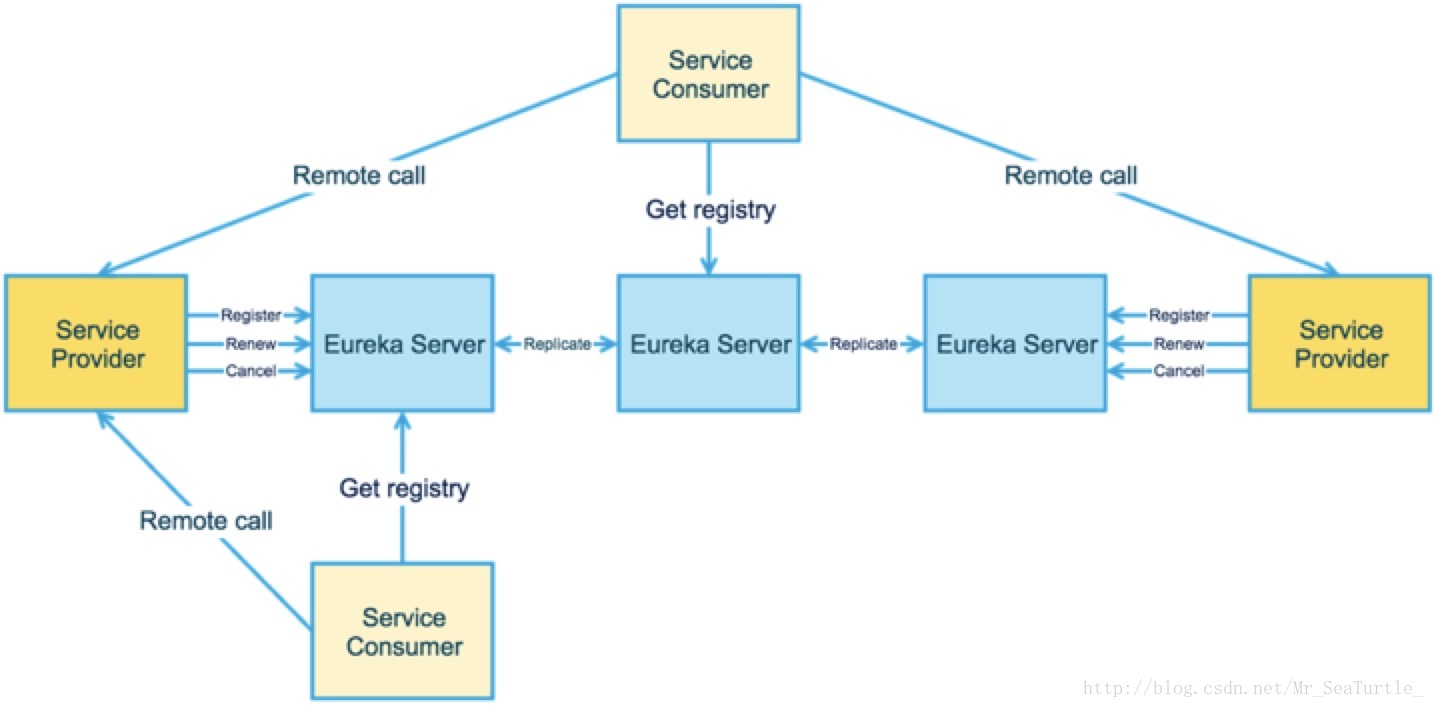
图片来源:携程技术中心
在多注册中心(server)的情况下,单个server在接收到服务的注册/更新信息的时候,它还会将这些信息同步给同样为server的peer(replicate to peer),为了避免广播风暴,这些信息只会传递一次,也就是说,接收到的server,不会再同步给自身的peer。
服务注册完成之后,当client需要进行服务调用的时候,就可以向server获取当前的服务列表,再根据服务列表中的ip地址以及端口号进行调用了。
更加具体一些的介绍,可以看这篇文章。
由于eureka的相关配置都是存储在配置文件中,因此如果需要动态增加server数量的话,就必须修改配置重启client,以确保server的一致性。所以在服务器端弹性配置上不够灵活。还有一个缺点是,由于一个client需要维持与多个server之间的联系,这个会占用额外的系统资源,另外这个框架在github上也有将近一年没有更新了。
Consul
Consul是目前较为流行的一个服务发现以及配置工具,Consul能够承担包括服务注册与发现、健康检查(health check)以及键值对存储等,同时,Consul还支持多个数据中心。
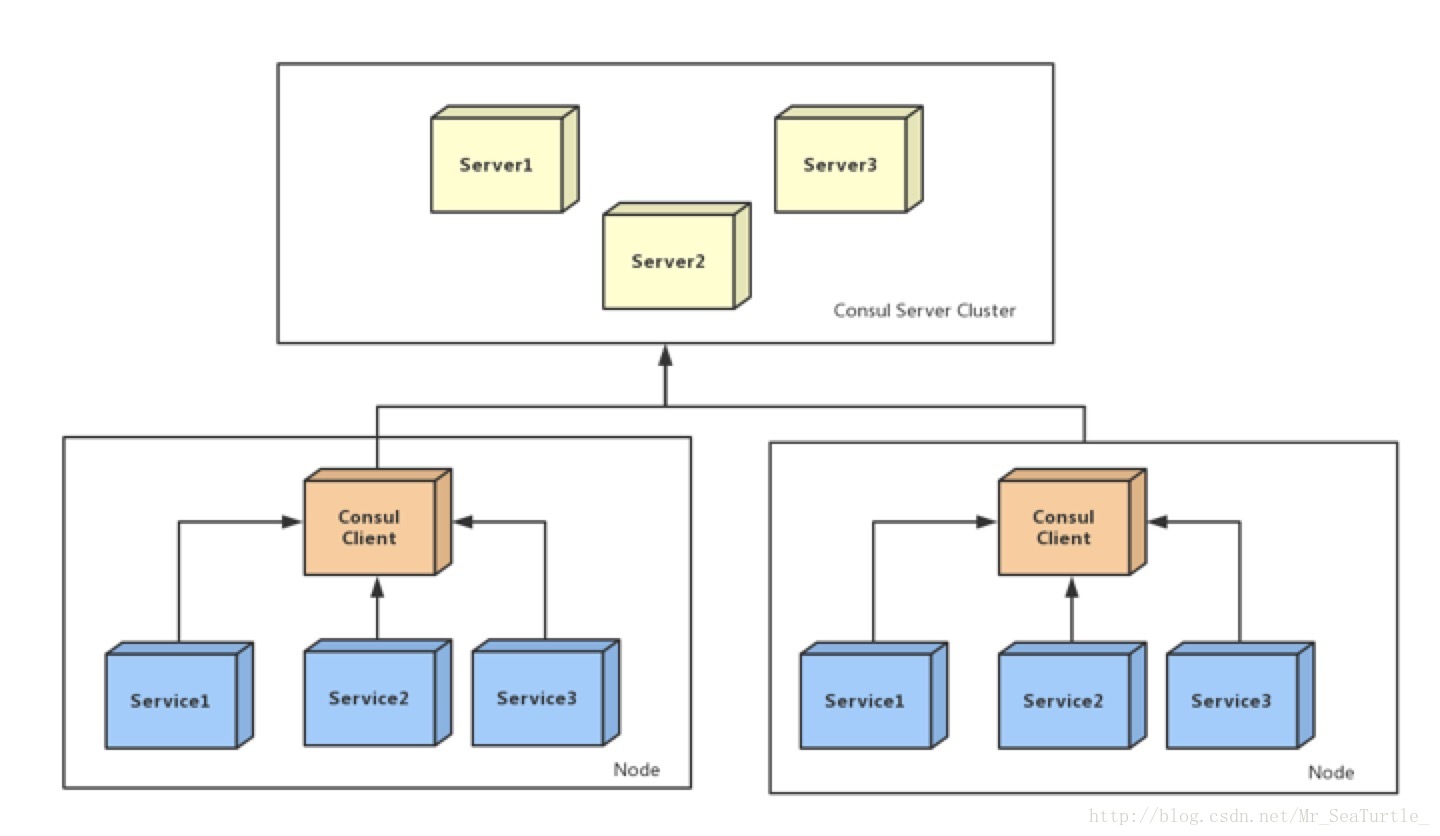
如上图所示,基于Consul的微服务一般都是集群,集群由一个个的Consul Agent组成,在这些Consul Agent里面,分为两种角色,Server 以及 Client。Consul是基于Raft协议实现的,这些Server里包含了Raft中的Leader以及follower。而client则只是向这些server进行键值对的读/写。
服务注册/反注册机制
当我们在本地启动Consul Agent之后,我们可以通过Consul的Restful Api(curl -request PUT http://consul/v1//agent/service/register)向Consul Agent注册服务信息,提交服务的端口号,ip地址,以及健康检查的方式。随后,这个Client就按照配置中的周期以及方式执行健康检查,当健康检查失败的时候,就会像Server Agent发送服务不可用的消息,这个服务就会被Consul标记为不可用了。
我们也能够通过Get方法请求相同的地址来获取当前agent中注册的所有服务信息。
小结
这篇文章通过三个方面介绍了服务发现。
服务端模式和客户端模式的区分,客户端模式下,所有客户端需要维护服务列表信息,负载均衡策略而服务端模式下则无需这些额外的实现。换而言之,在服务端模式下,更容易实现多语言的接入,更具有通用性,但是在客户端模式下,则具有了更快的响应时间以及更强的容灾能力。
服务发现中的CAP选择,由于微服务本身就是面向分布式的,因此所有框架都天然地支持分布式,那么具体的选择差异就体现在了可用性以及一致性上。Eureka认为部分服务注册信息没有实时同步实际上并不影响服务之间的依赖调用(一个服务节点失败了,客户端会选择另外一个节点进行重试),因此选择了高可用的架构。而Consul是基于Raft协议的,因此一致性更加重要。
参考文章
Consul官方文档 这里有Consul框架和其它框架的对比
Raft算法中文翻译 Raft是目前应用较为广泛的一致性算法,解决了分布式下的一致性问题,在服务发现中也被广泛运用,因此想要了解服务发现,建议也了解这个算法。
评论功能已关闭